

在计算机视觉技术中,许多方法用于评估输入并获得输出。图像分类,对象检测,对象跟踪和图像分割等技术可通过组合或单独使用来帮助创建计算机视觉。已经为深度学习创建了许多不同的架构,但是CNN架构是CV领域中常用的架构。该技术的缺点是数据集需求大,优化困难和黑匣子。
图片分类:
图像分类旨在根据图像的类型对图像中的内容进行分类。广泛使用的深度学习技术是卷积神经网络(CNN)。
预先标记的图像会创建训练数据集,包含图像的每个类都有单独的属性,这些属性由矢量表示。这些向量使用CNN进行训练,并使用新的数据集进行了改进。如果分类器的质量不足,则可以添加更多的测试集或训练集。
对象检测:
图像中对象的识别具有与图像分类不同的工作原理,为了对图像中的对象进行分类,须在边界框中确定这些对象。为了对图像中的对象进行分类,须在框中确定这些对象。尽管这些盒子的尺寸不同,但它们可能包含相同类别的图像。同样,检测包含大量对象的图像也需要增加计算机能力。已经开发出了诸如R-CNN,快速R-CNN,YOLO,单发多盒检测器(SSD)和基于区域的完全卷积网络之类的算法来快速发现这些事件。
对象跟踪:
对象跟踪是一种通过在下一幅图像中找到同一对象来跟踪图像中对象运动的方法。根据观察方法,对象跟踪技术可以分为三类:
生成技术:在此技术中,跟踪问题被公式化为搜索与目标模型相似的图像区域。主成分分析(PCA),独立成分分析(ICA),非负矩阵分解(NMF)是生成模型的示例,这些模型试图找到合适的原始数据表示形式。
判别技术:在判别方法中,监视被视为二进制分类问题,其目的是找到能将目标与背景区分开的决策极限。与生成方法不同,同时使用目标信息和背景信息。判别方法的示例是堆叠式自动编码器(SAE),卷积神经网络和支持向量机(SVM)。
混合技术:将这两种技术结合使用,并根据问题采用不同的技术。
图像分割:
将数字图像分为图像对象或像素集的过程。图像分割的目的是简化图像的表示并促进分析。
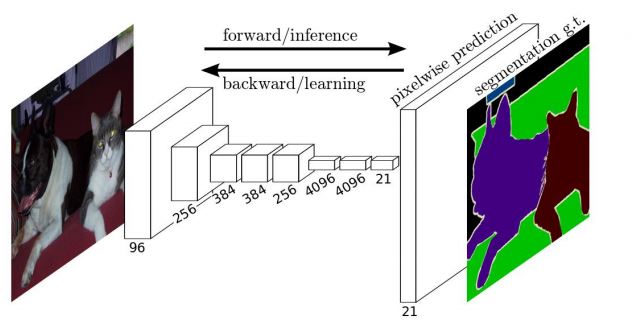
由于图像分割有许多不同的方法,因此可以使用Mask R-CNN和完全卷积网络(FCN)进行密集预测,而无需任何完全连接的层。
 微信在线咨询
微信在线咨询